Data “Self-Serve” is a buzzword that’s managed to stick around for a long time without a solution. However, I’m convinced that we can get partway there with simple data products rooted in familiar tools. One ubiquitious tool? Excel. Nearly everyone uses spreadsheets or similar productivity tools at work.
That leads me to meet stakeholders where they’re at: in Excel. And modern data warehouses like Snowflake make it really easy to do so. It’s an easy win if you’ve invested in Analytics Engineering to create clean datasets in your database. Let’s bring those datasets to your users.
Here’s how to connect Snowflake into Excel and enable live connections pivot tables in minutes. These are instructions for Windows specifically.
Step by Step Instructions
(1) Install the ODBC Driver
Click on the “Help” button in the Snowflake UI, go to “Download…” and select “ODBC Driver” and “Snowflake Repository”. Install from the file that downloads.


(2) Configure ODBC Driver
Go to your start menu and type in “ODBC” and click on ODBC Data Sources (64 bit)

Under User DSN, select Add…

Select SnowflakeDSIIDriver from the menu

Fill in the boxes as follows – though your individual situation may vary. My example uses SSO when an organization doesn’t allow direct usernames/passwords for Snowflake. Lots of options here and Snowflake has full documentation of options here.

Click on Test… to confirm it worked. Here’s the dialog if it did:

(3) Connect to database in Excel
Open Excel and go to the Data tab, click on Get Data and choose From Other Sources and pick From ODBC

From the window that pops up, pick the Snowflake connection and select OK

If successful, you’ll see a window with a dropdown showing your available databases. Use that dropdown to pick the database you want.

IMPORTANT: There is an easy way to load data directly into a Pivot Table at this point (thanks Jacob for this tip!) which will save you and teams time.
Once you select the database / schema / table you want, go to that “Load” button on the bottom and click the little down arrow next to it. Choose “Load to…”

The next menu that pops up will give you various options – pick the second one down saying PivotTable Report

DONE. You’re there. The data is now connected live to Snowflake and is available to pivot. I used Snowflake’s sample “Weather” table which I just learned has basically nothing in it, but that’s besides the point.
Parting notes
There are a couple interesting tidbits to pass both to your stakeholders as well as anyone concerned about Snowflake compute cost & data security.
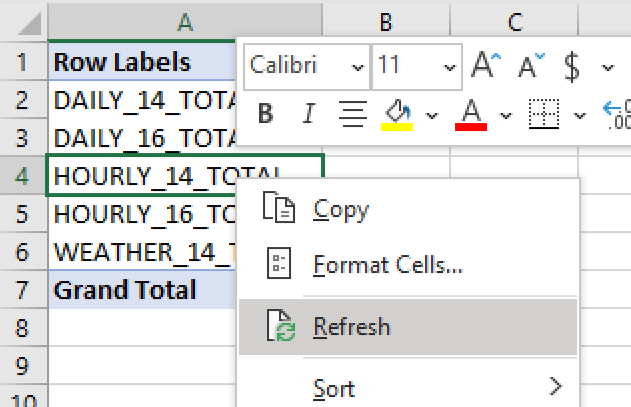
(1) Stakeholders can refresh data live from Snowflake any time. By right-clicking the pivot table and selecting “Refresh”. No more stakeholders asking you for the latest data – they can just get it anytime.
(2) Data is cached on the local machine, reducing compute costs & keeping things snappy for stakeholders. This satisfies worries from both stakeholders on performance (it’s REALLY snappy, even for huge tables) as well as those concerned on cost (compute only happens on refresh).
That’s it! Just a few installations and clicks and you’ve connected Snowflake live into Excel for any stakeholder. Happy self-serving.
